
Improving Exoskeleton Assistance Using Unsupervised Learning
I hate data labeling.
It's tedious, time intensive, and just flat out boring
POV you’re labeling data while Riverdale seasons 3-5 plays on your Macbook.
When training the Transformer in my previous paper I had to do this myself a ton to get the subject specific data to finetune the general walking model I regressed. The Transformer model was pretrained using supervised learning on 16 million paired data points of walking, and it successfully learned a general encoding of walking, expressible as both a human interpretable gait state (think variables like gait cycle location, speed, ground incline) and kinematics (e.g. foot angle, calf angle), which it then used to provide torque assistance through bilateral ankle exoskeletons. The transformer learned a general average gait across people, which mapped input kinematics (easily measured using the onboard sensors of an exoskeleton), to gait state (which were the labels that described walking).
However, wearing the exoskeleton itself changes how you walk, since it provides you torque assistance and the way humans adapto that assistance is not easy to predict ahead of time. Additionally, but averages don't walk, people do (as an aside, averages being way less useful than you expect is something that's come up over and over in stuff I've read), so the finetuning data was necessary for the model to learn how each specific subject in my study walked.
Thankfully the pretrained model was generally good enough that we didn't need much of the finetuning data , but still the fact that I had to do this manually for this approach to work placed serious logistical constraints on this method. Plus if we ever want this finetuning to happen outside the lab, it's infeasible to expect labeling. What are we gonna do, instrument people with Vicon markers and send them home?
If we wanted to have pretrain-finetune method work at scale, we'd need to discover a way to adapt a pretrained network on personalized walking data from individuals without needing manual labeling.
We trained a network to adapt to exoskeleton walking without any labels at all.
Our approach treats the problem as unsupervised domain adaptation. Large labeled datasets of normative walking form the basis for pretraining a model. This training instills knowledge of baseline locomotion and the mapping between input kinematics and the human-interpretable gait state labels. We can then adapt the model to exoskeleton-assisted walking using only the kinematics sensor measurements from people wearing the device, with no labels required.
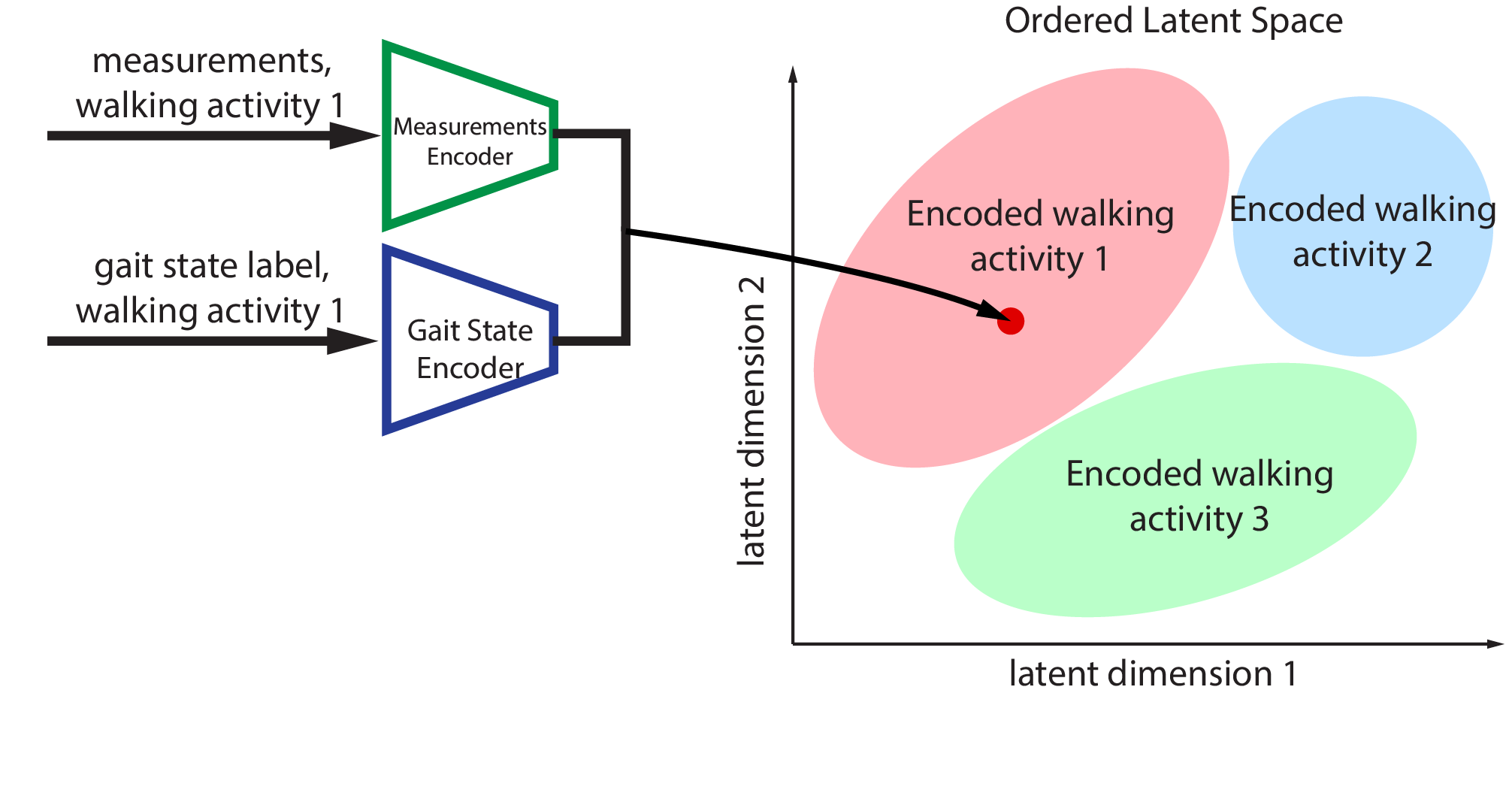
A cartoon of what the latent space for walking looks like. Each colored blob is a different type of walking activity (e.g. stair ascent, fast walking, downhill walking). The idea is two kinds of encoders (represented by neural networks) can encode the data for the same fundamental task to the same point in the latent space.
The core idea behind this was to use the concept of the latent space. Think of it like a shared high dimensional vector space where each vector represents a type of walking. Some vector in there represents, for instance, level ground walking at 1 m/s, and a nearby vector represents walking at 1.1 m/s. A vector that's further away in one dimension may encode a more distinct kind of walking, like walking on stairs. Each of these points is expressible as a set of kinematics, and, crucially, a gait state. This was directly inspired by what the LLM guys did with approaches like CLIP, in which the word "cat" and a picture of a cat map to the same shared embedding space. The theory I had was that with careful training, the network could learn an embedding space that captured the fundamental essence of walking, and could personalize this embedding using only unlabeled kinematics data.
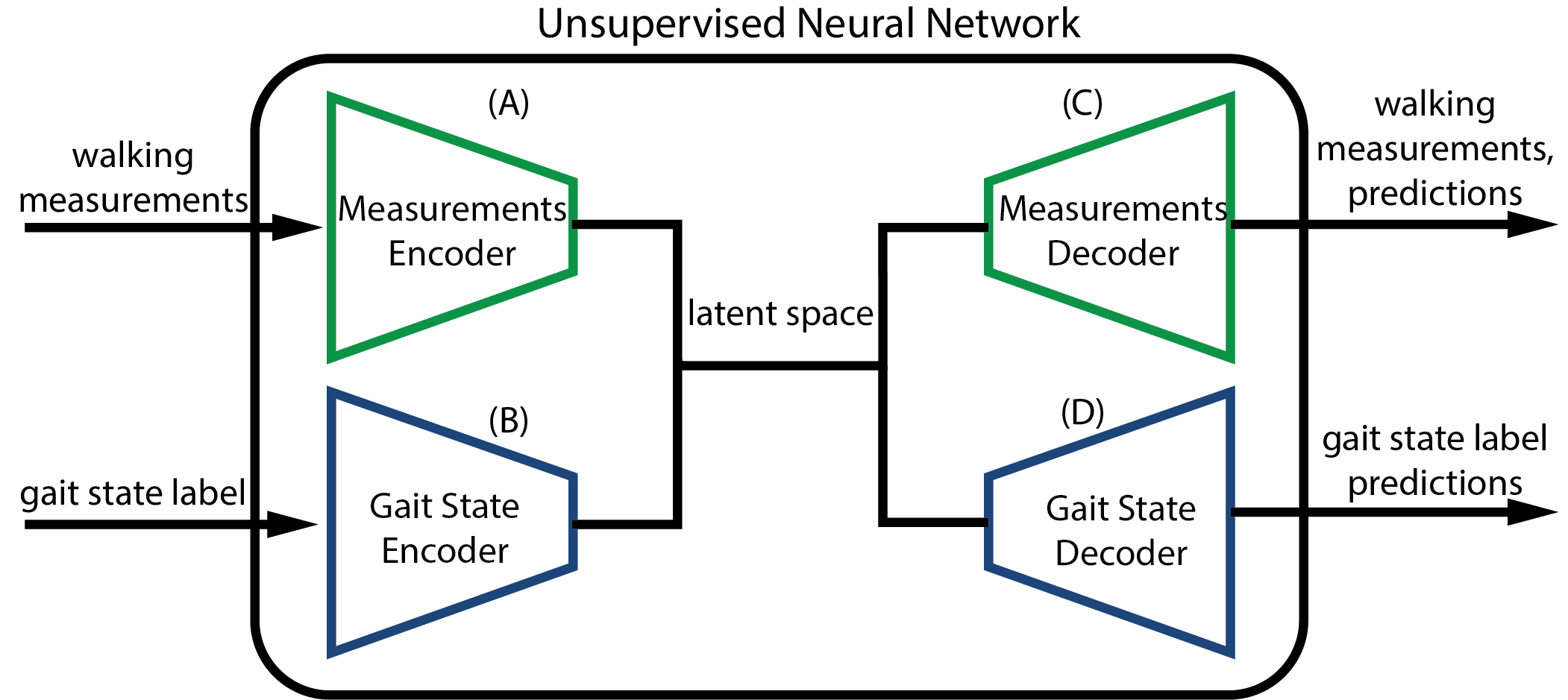
We built a four-network system: two encoders (one for kinematics, one for gait labels) and two decoders that can reconstruct either representation from the shared space.
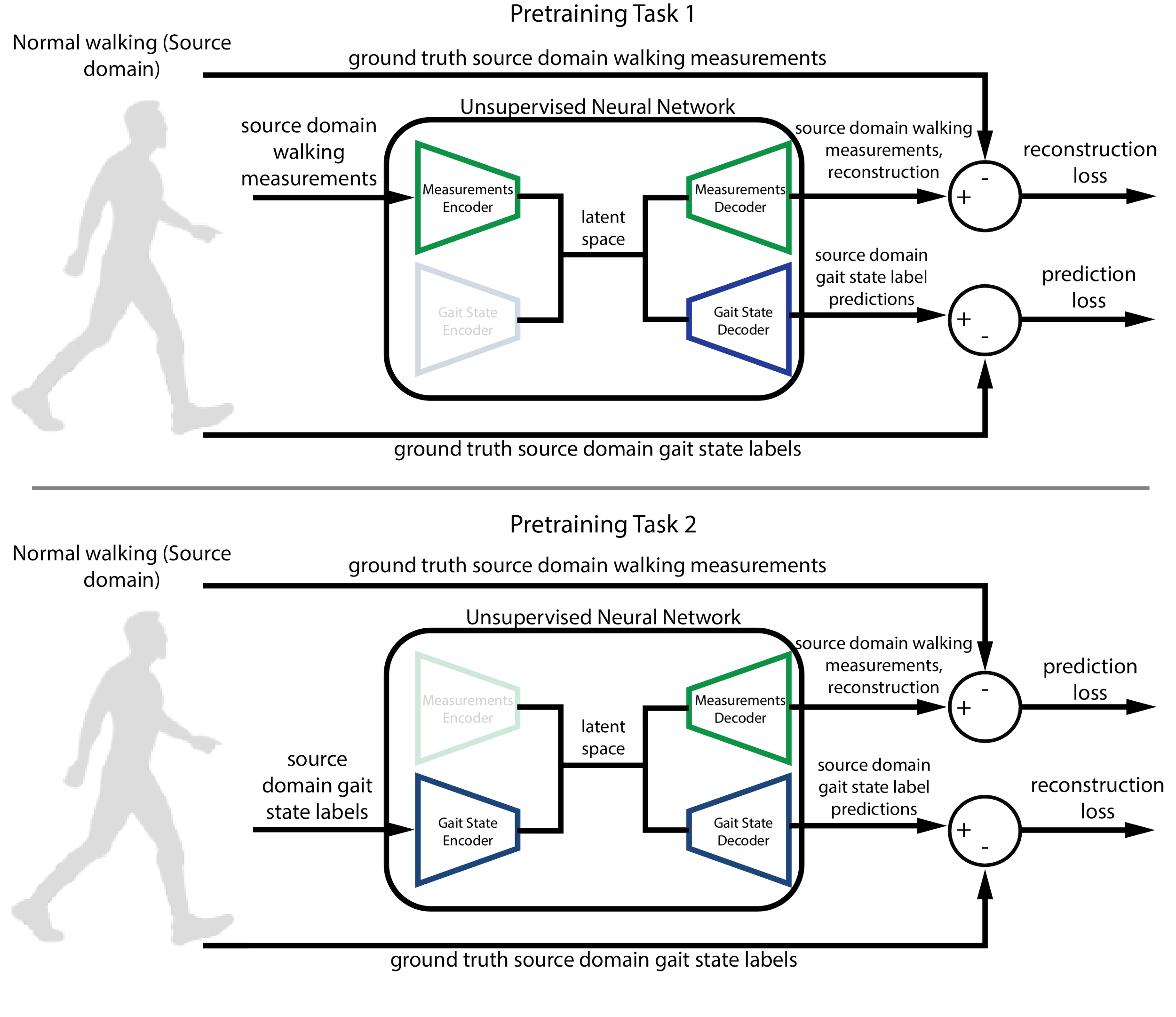
During pretraining on normative data, the kinematics and gait state encoders were trained to compress walking kinematics into the same latent embedding, while the gait state decoder was trained to predict its gait state label (which we had access to). The kinematics decoder was trained to reconstruct itself using the embedding .
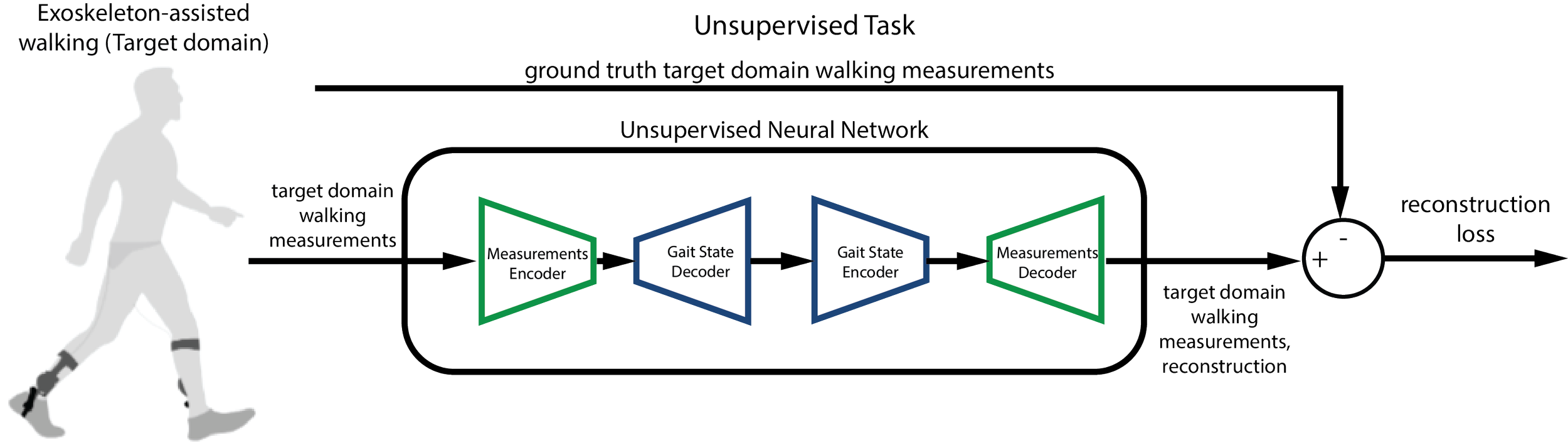
During adaptation, we freeze the gait state networks (since we wouldn't have access to gait state labels during unsupervised finetuning) and let the kinematics networks update using only the reconstruction objective on unlabeled exoskeleton data, along with a KL divergence loss to preserve the knowledge gained during finetuning. The model effectively learns to re-express its knowledge of walking in the context of assisted locomotion, without ever seeing a single label from the target domain.
We validated the method on walking data from 14 participants wearing a powered ankle exoskeleton, across a range of terrains including level ground, inclines, and stairs.
Our adapted model significantly outperformed the pretrained-only baseline.
Gait phase went from 8.7% phase RMSE to 8.0%, incline went from 2.3 deg to 2.1 deg (significant, though not huge) and classification for steps on stairs improved from 61.8% to 82.4%(!!).
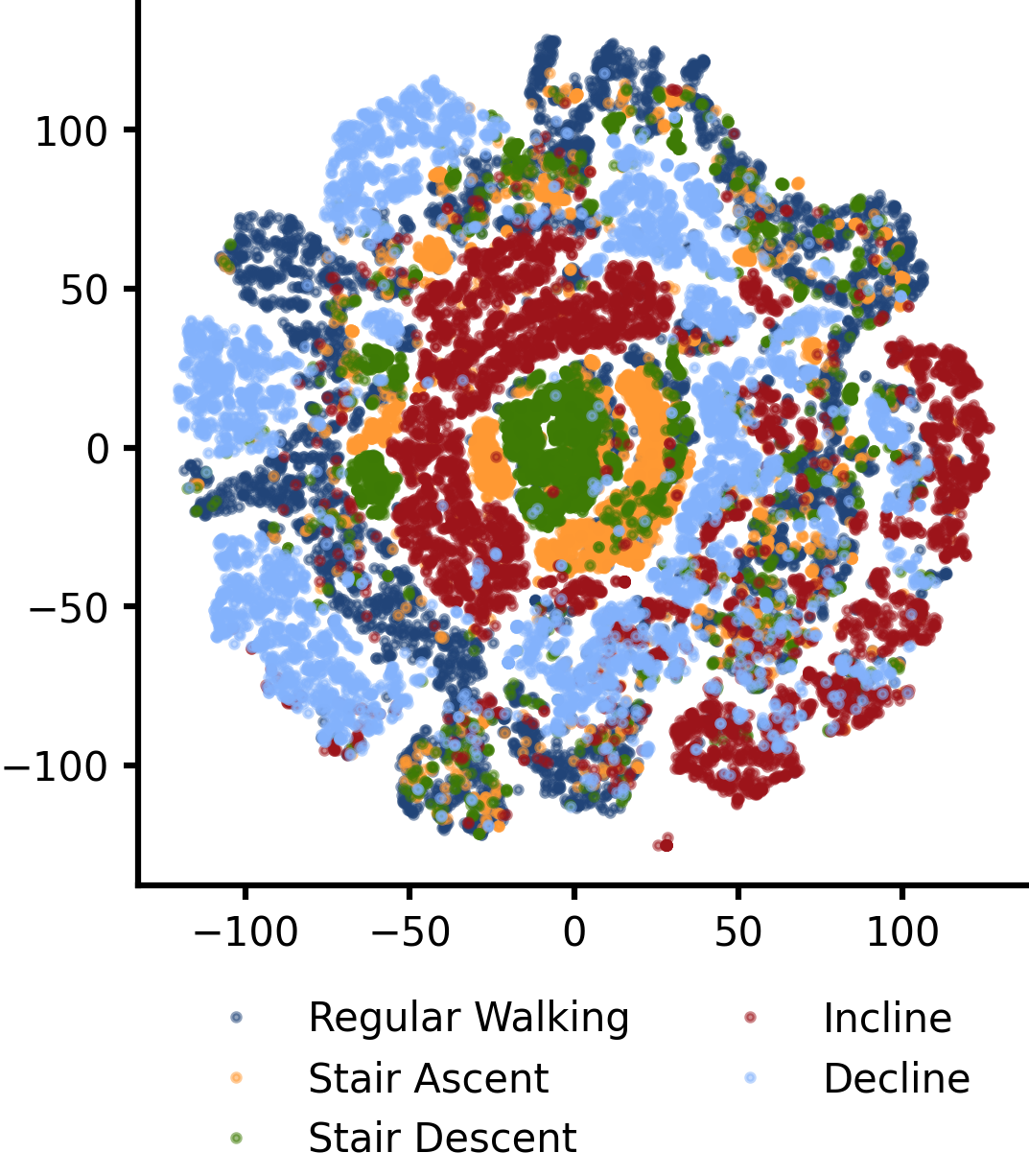
What I found interesting was that the latent embedding emerged consistently across training runs. I suspected it would given the previous Transformers paper, and my bet is that the same “kind” of latent space emerged consistently across training runs. Walking is a highly structured task, and during the learning process the Transformer really didn't need a lot of data to converge to a steady low loss (only a few epochs). This makes me think that what's more important for training these models is depth not breadth; if you have a data collection budget of 100 steps, it's better to have 1 step at a 100 different conditions than 100 steps in one conditions. In fact, I’d be really interested to see if something like the Platonic representation hypothesis holds true for walking (and perhaps even human motion itself), and if that’s possible to test this with the comparatively smaller amount of data we have for locomotion.
A visualization of the learned latent space (using t-SNE). Different activit modes are highlighted with different colors. Note the circular structures of different radii. Walking is cyclic and the model learned that. The model also learned to separate different activity modes.
Second, the method worked! we squeezed out performance gains using only unlabeled exoskeleton data. They weren't particularly large, but I think that's because we only had something like 24k datapoints per person, as opposed to 16 million. I think with more unlabeled data, we could potentially get more performance increases. And this method enables mass scale collection, as we just need to have people walk over a variety of conditions without any labels, just storing the kinematic measurements.
One last thing is that I really like the concept of the latent space itself. Being able to represent abstract concepts like walking in vector form opens the door for some interesting followups, for isntance, what if we did an encoder-decoder pair for joint torques? the exoskeleton torque data could fit neatly into that set, and we could potentially just replace the gait state encoders-decoder entirely with the output of a joint torque decoder, since what we care about is torque assistance. In silico, the pretrained Transformer evaluated on the validation subjects walking featured 1.6% phase RMSE, 0.07 m/s speed RMSE, 0.7 degrees incline RMSE, and a 95%+ accuracy on classifying stairs samples. Pretty good! We were able to outdo the EKF in silico performance while also classifying stairs, which boded well for this approach.